This chapter describes
Processes running on different computers can only communicate if there is some form of connection between the computers. This chapter describes the basic principles of networking. The knowledge of this chapter is needed in the following chapter to understand the potential and limitations offered by the TCP/IP protocol suite, which is used by all UNIX interprocessor communication facilities.
There are three basic methods for transmitting data from one endpoint to another endpoint via electronic networks:
In circuit switching, the oldest method, a link has to be set up along
all the nodes forming
a path between the two hosts. This link has to be maintained for the whole
duration of the transmission. If one node between the two hosts crashes
or is removed, the connection is broken. A typical use of this
type of switching is using the phone. After dialing, one cable is
reserved. It does not matter if one speaks or not. This type of communication
is therefore expensive, as resources are often not used effectively.
In the days of multimedia (video, audio, etc.) with the need for a
constant data stream to be transmitted in a certain time this
technique is getting more attention again. When circuit switching
methods are used data can be transferred without additional information
like destination address, control information etc. (one does not have
to do anything to maintain a phone call).
As circuit switching is very expensive new methods for transmitting data
were needed. Message switching takes into account that computers
do not exchange data all the time. With message switching no real connection
is established between the
two hosts. All messages are transmitted independently. Therefore all
messages need the full information about the destination, and other
control information. Messages can have
various sizes up to a fixed limit. All nodes along the path must be able
to store the entire incoming message and have control facilities for
forwarding the message to a node in the right direction. This technique is
therefore called store-and-forward. If no suitable node is available,
and a fixed number of retries are unsuccessful, an error message is normally
generated and sent back to the origin. As multiple paths are often
available for routing, the failure of one node does not normally matter.
If too many hosts try to exchange data serious congestion can result.
Message switched data normally needs much longer to be transferred to
the endpoint, as messages are stored for variable times in the nodes between
the endpoints. Message switching makes much better use of available resources
than circuit switching.
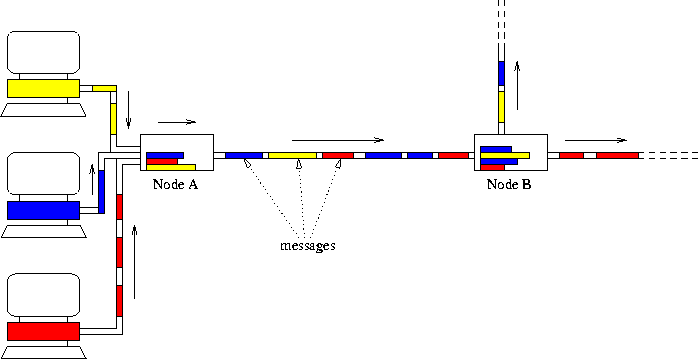
Figure 10 illustrates message switching.
A special combined form of message and circuit switching is called
packed switching. Here the original data is split into very small
fixed length
packets. These packets again need some information about the
destination. The advantage of these small packets is that they can be
forwarded very fast. The amount of storage needed is decreased. This
allows much higher throughput of data than message passing. At the
endpoint the packets are reassembled. A very popular method,
ATM (Asynchronous Transfer Mode), uses this technique. ATM is described
in detail in [CCR95/2].
The most used technique with computer networks is message switching.
The other techniques are not discussed further.
One might think that connection-oriented communication is equivalent to using circuit switching and connectionless communication equivalent to message switching. The first is not really the case, although they are closely connected. Connection-oriented protocols like TCP (described in Chapter 5.9) use messages to transfer data. TCP establishes a virtual connection, which has no guarantee about throughput, but emulates all the other properties of a circuit switched connection.
Message passing techniques differ mainly in the way they deal with the following issues:
Normally there are multiple ways to designate with whom to communicate:
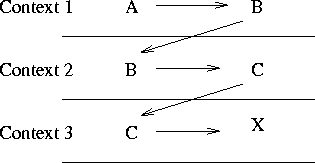
In all cases it is necessary that the name (``A'' to ``G'') has to be
mapped to the real object or destination. This can only be done within
a specific context (also called space). In a network for
example the name ``A'' of a computer
can be resolved by its address ``B'', which in turn can be used in the
next layer and so on. Figure 11 illustrates this.
On a UNIX system the simplest way to address a message is to use the process identifier of the receiving address. However, if processes communicate via a network, a process number is not unique enough. A more precise destination identifier, e.g. the tuple {host address, process id} has be used. To use the direct naming scheme, the client must know the physical network address of the node where the server process runs on. If the network card of the server is replaced this information becomes invalid. Therefore this static binding technique is seldom used. A global name space of addresses has to be used. A global name is then an identifier that is bound dynamically to the server's network address at boot time (or changed even later).
To have the ability to address anyone in a given context the name
has to be unique. Logically names can only conflict if their contents
are equal. An example is the process ids in a network: their
naming contexts conflict. A solution is to use federated
namespaces which are constructed out of several distinct and independent
name contexts. Often hierarchical concatenation can be used to build
a global name space. An example is how to make an address of a person unique
in the the universe:
milky way/solar system/planet/country/city/street name/house number/flat number/name
This system can also be used for networks, where the result is to
identify every process on all computers unequivocally. Here is an example for
a network with subnetworks:
network/subnetwork/host name/process id
Another way for all participants to agree on a partition of ranges,
e.g. computer A only has process ids from 0 - 999, computer B from
1000 - 1999 and so on.
Both techniques can be combined to achieve a global name space.
To archive dynamic binding multiple possibilities exist. To map
global names to network addresses a file could be used. The use of
a file, however, gets impractical if the network is big. Also this file
has to be consistent and transmitted to every host.
Even if the file is accessible via a network file system it has still
to be updated every time a new computer is connected to the network or
removed from it.
Broadcasting of all addresses might be useful in small networks,
e.g. in token rings or Ethernets where all messages are seen by all
computers anyway. In large networks broadcasting is often too expensive.
A method often used is the use of name servers, which are used to resolve global names or at least parts of a global name. A client asks a name server for the network address of a global name. The client can then communicate directly with the intended server. The only problem is: how to contact a name server? Name servers can either have a fixed well-known address, or a client can broadcast a message on the local network with the name server responding with its address. Often more than one name server is used to avoid problems when the only name server is down or congested with too many requests.
Different types of computers with different kinds of CPUs exist. The same information is therefore not always represented in the same way. Problems especially occur due to:
Nowadays the size of a byte is quite stable: it consists of 8 bits on
nearly all computers. However this was not always the case. Therefore in
networking the term octet is often used to specify that exactly
8 bits are meant. In this document the term octet is not used to avoid
confusion.
The order of bytes in data sizes longer than 8 bits is still a major
problem. Two different orders of bits are used: the
little endian order where the most significant byte comes first,
and the big endian order where the most significant byte is
the last byte. Figure 12 illustrates this.
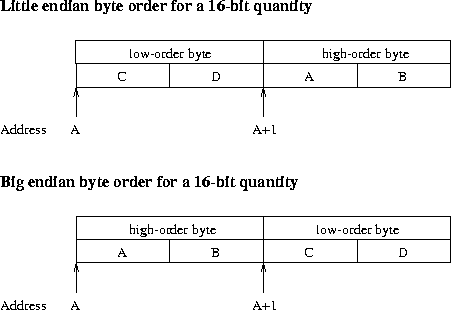
The Motorola 680x0 series, Sun SPARCstations and IBM mainframes use the big
endian byte order, while DEC VAXes and Intel 80x86 for example use the
little endian byte order.
The representation of floating point numbers also differs. Most modern computers
use the IEEE 754 standard to represent single-precision floating point numbers.
The size of pointers is not really an issue, as pointers are normally
meaningless on other computers anyway. If space for pointers has to be reserved,
one should consider that the number of 64-bit computers is increasing rapidly.
The ASCII (American Standard of Information Interchange) character set is
used on most common computers, although some IBM mainframes still
use EBCDIC to encode characters.
If different computers have to exchange data structures
one has to consider the alignment of data. Some computers align longwords
on 16-bit boundaries, others on 64-bit boundaries. Therefore one has to be
careful when using the same data structures to exchange data between different
computer types. Even compilers sometimes align data on the same system
differently.
As one can see the need for data conversion is inherent in networking. The problem of byte ordering is often solved in declaring a network byte order which everyone has to use if data is exchanged. Most text is exchanged using the ASCII character set. The other issues are often handled as application specific.
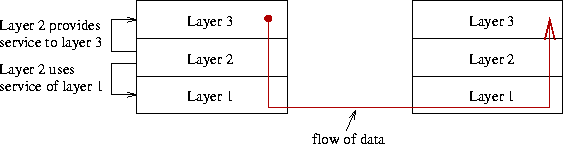
A protocol is a set of rules and conventions between the communicating participants [Stev90]. They can be very complex. One engineering technique that deals with this complexity is layering. Therefore protocols are normally designed in layers. Every layer N provides a service to layer N+1, and uses the service of the layer N-1 below. Layer N on one computer communicates virtually directly with the same layer on the other computer, even if the data flows down the layers on the first one and up on the second one. Figure 13 illustrates this. Between the different layers different protocols are used. The result is called protocol stack. A protocol suite is the combination of different protocols at various levels.
A layered approach is useful for several reasons [Elb94]:
All data has to flow through all layers. If individual layers do not add much functionality, this approach is inefficient and leads to poor performance.
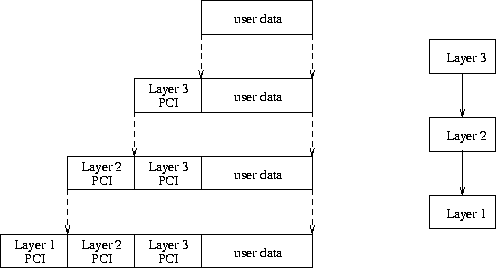
An encapsulation technique is normally used to exchange protocol information. Layer N takes the data from the layer above, adds its own protocol control information and handles this to the next layer down. This is comparable to putting something in an envelope, putting this together with other information into a bigger envelope, and so on. Figure 14 illustrates this process.
The Open System Interconnection (OSI) reference model, as established in ISO 7498, is often used to compare different networking architectures. It is a formal
description of a protocol stack architecture. The OSI reference model was
positioned as a framework for the development of an extensible and scalable protocol suite for communication among open systems [Elb94]. The OSI
reference model and implementations of it have to be distinguished.
The OSI reference model consists of seven layers (Figure 15).
The principle is that each layer can be specified and implemented more
or less independently of those above and below as long the interfaces are
consistent.
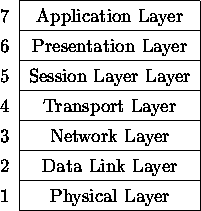
The layer definitions of the OSI reference model are commonly used and generally accepted, although not all layers and services are present in most common networks.
The application layer contains all the utilities that support application programs. This layer does not include applications itself. Services like file transfer, e-mail, virtual terminals and others are part of the application layer.
The presentation layer is responsible for presenting the data in a way that is meaningful for an application. This includes details about the CPU and operating system dependent encoding of data as described above. This allows the application layer to communicate without regard to the actual presentation of data on a specific system.
The session layer manages the data exchange between open systems in an orderly fashion [Elb94]. It creates, manages, and terminates the dialogues between the users.
The transport layer takes packets of data from the Network layer and assembles them into messages. Two different kinds of services are supported: connection-oriented and connectionless services. The first one is used to provide end-to-end, error-free service to the session layer. The support of connectionless transport services is minimal; these are used if the need for the services above is not critical.
The network layer is responsible for routing from end to end within a network [Elb94]. The services provided include network addressing, blocking and segmenting message units, switching and routing, and controlling congestion. As in the transport layer connectionless and connection-oriented services exist.
The data link layer is responsible for the error-free transport of data between adjacent systems. It shields the upper layers from details concerning the physical transmission. The data link layer contains services like media management, framing, and flow control. Three types of service are provided: connection-oriented, acknowledged connectionless and unacknowledged connectionless.
The physical layer is responsible for the actual transport of data. Here
functional, electrical and procedural characteristics are specified:
signal timing, the voltage levels, connector types, etc.
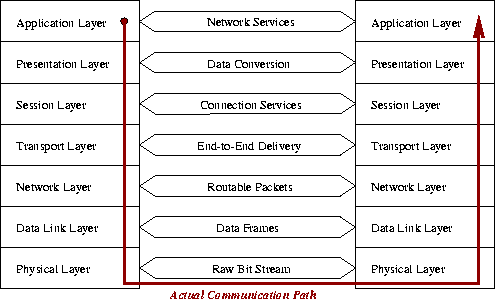
The flow of data between endpoint in the OSI model is summarized in Figure 16.
The OSI Reference Model can be criticized in many areas. Some of its problems are:
Further problems of the OSI Reference Model are discussed in [Day95] and [Tan88, page 30ff, 274ff]
A huge number of different network protocol suites have been developed. Some of the more commonly used ones are:
TCP/IP is used mostly to connect different systems, as it is supported by nearly all vendors/products, especially in the UNIX environment. BSD 4.2 was the first operating system which used TCP/IP. As the source code is free, this led to widespread use and implementation of this protocol.
Networking adds a lot of complexity. The layering technique is used in multiple levels to deal with this increased complexity. The OSI Reference Model is often used to describe networking in theory, even if this model has shortcomings. The most used protocol suite in the UNIX world is TCP/IP and is discussed in the following chapter.